Project Proposal - Home Credit Risk Analysis
This is our project proposal for our CS 7641 Group Project, which aims to analyze home credit risk. This report is the first iteration of our project, which we will use to guide our project as we move forward. This website will be updated as we progress through the project, and will be finalized at the end of the semester, with a completed version of our home credit risk prediction.
Table of contents
- Project Proposal - Home Credit Risk Analysis
- Video
- Introduction/Background
- Problem Definition
- Methods
- Potential Results & Discussion
- Contributions Table
- Project Timeline - Gantt Chart
- References
Video

Introduction/Background
One of the main functions of banks and other financial institutions is to act as money lenders and provide loans and credit lines for customers. However, in order for them to operate profitably and reduce risk of people defaulting on payments, they need to be able to assess an individual’s credibility. This is also applicable to determining the amount of interest they should charge on the loan and whether or not they should even offer the loan at all. This project aims to create a model for financial institutions to predict the credit risk of their borrowers. We will use the Home Credit Group dataset from Kaggle for this project, which has numerous data points about loan applicants and their credit risk. The dataset can be found at this link.
Problem Definition
With the housing market facing many uncertainties, many individuals struggle to get loans due to insufficient, or even non-existent credit history. Distrustworthy lenders capitalize on these individuals, while banks lose out on potential customers due to inconsistent evaluations. Creating predictions for repayment likelihood ensures that clients capable of paying out loans are not rejected. Identifying potential defaulters before granting a loan mitigates losses, but manually assessing risk profiles is time-consuming, prone to biases, and lacks consistency. Developing a model to classify individuals into repayment risk categories will reduce manual intervention, increase consistency with risk evaluations, and decrease the default rate.
Methods
Our model will classify credit applicants into low, medium, or high risk categories based on their credit history, and thus we can model our problem as a supervised classification problem. Before applying supervised learning, we will transform and cluster our data using unsupervised methods, giving us crucial information to help design our supervised algorithms.
When exploring and predicting on this dataset, we will use a litany of supervised and unsupervised methods. Our preliminary plan involves using simple unsupervised techniques such as K-means Clustering, Gaussian Mixture Models and Principal Component Analysis. These methods would allow us to understand the groupings/classifications of our data, as well as assist with feature selection and outlier removal.
After these steps, we will move on to creating a supervised model, using techniques such as Support Vector Machines or Decision Trees. This will comprise the bulk of our results, and will likely require tuning and hyperparameter experimentation.
Potential Results & Discussion
To evaluate our results and determine if our techniques are effective at distinguishing high and low risk borrowers, we are going to use a variety of scores and metrics to ensure our predictions and clusters are properly fit.
For clustering algorithms, we plan to report the Rand score and the Adjusted Mutual Information score, since these provide good feedback about the quality of our clustering. We are able to use the Adjusted Mutual Information score since we have access to the ground truth labels for our data points.
For our supervised learning algorithms, we will use classification goodness-of-fit metrics such as the precision score, the accuracy score, and the confusion matrix to better understand where our model succeeds and where it stumbles.
Contributions Table
| Yash Gupta | Reetesh Sudhakar | Nityam Bhachawat | Mark Nathaniel Glinberg |
|---|---|---|---|
| Methods, Potential Results & Discussion | GitHub repository, Project Website & Documentation, Problem Definition | Video Presentation, Dataset Exploration | Project Timeline, Project Introduction/Background, Literature Review |
Project Timeline - Gantt Chart
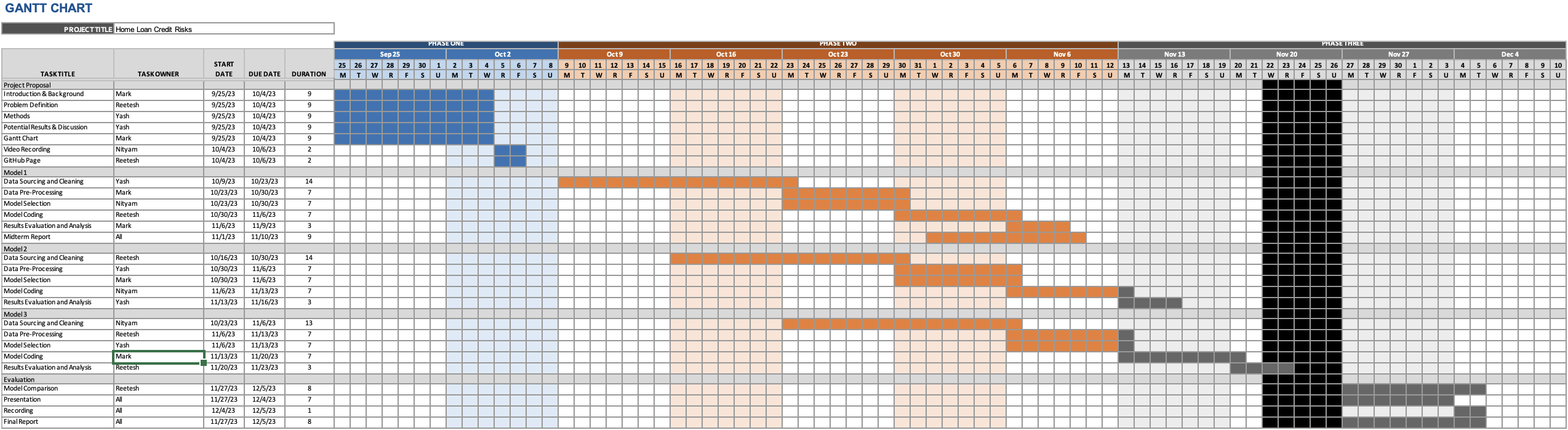 To access view the Excel file and download it, please click here.
To access view the Excel file and download it, please click here.
References
- Bao, W., Lianju, N., & Yue, K. (2019). Integration of unsupervised and supervised machine learning algorithms for credit risk assessment. Expert Systems with Applications, 128, 301–315. https://doi.org/10.1016/j.eswa.2019.02.033
- de Castro Vieira, J. R., Barboza, F., Sobreiro, V. A., & Kimura, H. (2019). Machine learning models for credit analysis improvements: Predicting low-income families’ default. Applied Soft Computing, 83, 105640. https://doi.org/10.1016/j.asoc.2019.105640
- Emad Azhar Ali, S., Sajjad Hussain Rizvi, S., Lai, F.-W., Faizan Ali, R., & Ali Jan, A. (2021). Predicting Delinquency on Mortgage Loans: An Exhaustive Parametric Comparison of Machine Learning Techniques. Vol12 - Issue 1, Volume 12(Issue 1), 1–13. https://doi.org/10.24867/ijiem-2021-1-272
- Krainer, J., & Laderman, E. (2013). Mortgage Loan Securitization and Relative Loan Performance. Journal of Financial Services Research, 45(1), 39–66. https://doi.org/10.1007/s10693-013-0161-7